Vos tentatives
Par définition, lorsque vous «limitez» les valeurs de votre code, vous causez une saturation. Ce n'est peut-être pas une saturation dans le sens d'un débordement de votre short, mais vous déformez toujours la vague lorsqu'elle dépasse un certain point. Voici un exemple:
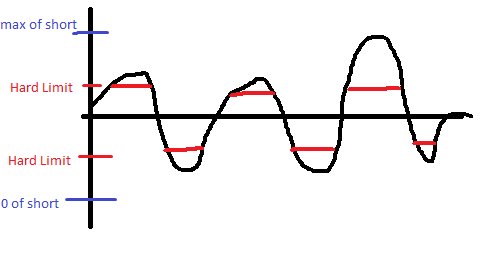
Je me rends compte que vous ne vous limitez probablement pas au fond, mais je l'avais déjà dessiné avant de m'en rendre compte.
Donc, en d'autres termes, la méthode de limitation stricte ne fonctionnera pas.
Maintenant, pour votre deuxième approche, cette méthode vous amènera à faire ce que certaines personnes audio font intentionnellement. Vous faites en sorte que chaque image soit aussi forte que possible. Cette méthode peut fonctionner correctement si vous obtenez la bonne mise à l'échelle et que votre musique sonne toujours fort, mais ce n'est pas génial pour la plupart des gens.
Une solution
Si vous connaissez le gain effectif maximal possible que votre système peut créer, vous pouvez diviser votre contribution par autant. Pour comprendre ce que cela serait, vous devrez parcourir votre code et déterminer quelle est l'entrée maximale, lui donner un gain de x, déterminer quelle est la sortie maximale en termes de x, puis déterminer dans quoi x devrait être afin de ne jamais saturer. Vous appliqueriez ce gain à votre signal audio entrant avant de faire quoi que ce soit d'autre.
Cette solution est correcte, mais n'est pas idéale pour tout le monde car votre plage dynamique peut être un peu blessée car vous ne le faites généralement pas. fonctionner à l'entrée max tout le temps.
L'autre solution est de faire un gain automatique. Cette méthode est similaire à la méthode précédente, mais votre gain changera avec le temps. Pour ce faire, vous pouvez vérifier la valeur maximale de chaque image de votre entrée. Vous utiliserez pour stocker ce numéro et placer un simple filtre passe-bas sur vos valeurs max et décider du gain à appliquer avec cette valeur.
Voici un exemple de ce que serait votre gain par rapport au volume d'entrée:
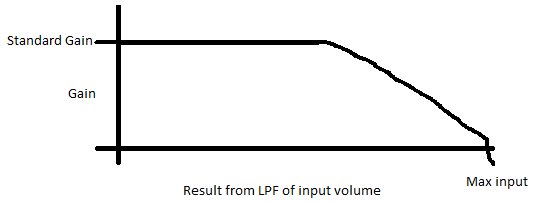
Avec ce type de système, la plupart de votre audio aura une plage dynamique élevée, mais lorsque vous vous rapprochez du volume maximum, vous pouvez réduire lentement votre gain.
Données Analyse
Si vous voulez savoir quel type de valeurs votre système reçoit réellement en temps réel, vous aurez besoin d'un type de sortie de débogage. Cette sortie changera en fonction de la plate-forme sur laquelle vous travaillez, mais voici un aperçu général de ce que vous feriez. Si vous êtes dans un environnement intégré, vous aurez besoin d'une sortie série. Ce que vous ferez, c'est à certaines étapes de la sortie de votre code vers un fichier ou un écran ou quelque chose à partir duquel vous pouvez récupérer les données. Prenez ces données et mettez-les dans Excel de Matlab et représentez-les toutes en fonction du temps. Vous serez probablement très facilement en mesure de dire où les choses vont mal.
Méthode très simple
Saturez-vous votre double? Cela ne sonne pas comme ça, au lieu de cela, on dirait que vous êtes saturé lorsque vous passez à un court métrage. Une manière très simple et "sale" de faire ceci est de convertir le maximum de votre double (cette valeur est différente selon votre plateforme) et de le mettre à l'échelle pour être la valeur maximum de votre short. Cela garantira qu'en supposant que vous ne débordiez pas votre double, vous ne déborderez pas non plus votre short. Cela entraînera très probablement une sortie beaucoup plus douce que votre entrée. Vous aurez juste besoin de jouer et d'utiliser certaines des analyses de données que j'ai décrites ci-dessus pour que le système fonctionne parfaitement pour vous.
Des méthodes plus avancées qui ne s'appliquent probablement pas à vous fort>
Dans le monde numérique, il y a un compromis entre résolution et plage dynamique. Cela signifie que vous avez un nombre fixe de bits donnés à votre audio. Si vous diminuez la plage dans laquelle votre audio peut se trouver, vous augmentez le nombre de bits par plage dont vous disposez. Si vous pensez à cela dans le sens de volts et que vous avez une entrée 0-5v et un adc 10 bits, vous avez 10 bits à donner à une plage 5v, généralement cela se fait de manière linéaire. Donc 0b0000000000 = 0v, 0b1111111111 = 5v et vous attribuez linéairement les tensions aux bits. En réalité, avec l'audio, ce n'est pas toujours une bonne utilisation de vos bits.
Dans le cas de la voix, vos tensions par rapport à la probabilité de ces tensions ressemblent à ceci:
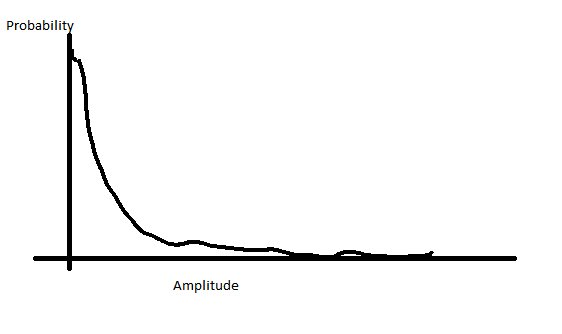
Cela signifie que vous avez beaucoup plus de voix dans l'amplitude inférieure et juste un peu dans la quantité élevée. Ainsi, au lieu d'affecter vos bits de manière linéaire, vous pouvez remapper vos bits pour avoir plus de pas dans la plage d'amplitude inférieure et donc moins dans la plage d'amplitude supérieure. Cela vous donne le meilleur des deux mondes, une résolution là où se trouve la majeure partie de votre audio, mais limite votre saturation en augmentant votre plage dynamique.
À présent, ce remappage changera la façon dont vos filtres agissent et devra probablement retravaillez vos filtres, mais c'est pourquoi c'est dans la section "avancé". De plus, puisque vous faites votre travail avec un double et que vous le convertissez en court-métrage, votre court devra probablement être linéaire de toute façon. Votre double vous donne déjà beaucoup plus de précision que ce que votre short vous donnera donc il n'est probablement pas nécessaire d'utiliser cette méthode.